在前几天发布了一篇介绍内存对齐的文章(c语言解剖课:内存对齐并不仅仅只是和结构体的成员变量有关),内存对齐主要指的是变量、数据类型,尤其是自定义数据类型的内存地址必须是自身对齐系数的倍数以及相关知识。
其实,除了内存地址和对齐系数是倍数之外,还有一些非常重要的因素影响对变量访问的性能,例如CPU每次读取的字节数、操作系统是否匹配CPU的读取能力、数据总线提供的传输的宽度,决定了对内存的寻址能力。
我们就来介绍一下这些与内存对齐相关的重要概念。
位、字节、字、双字
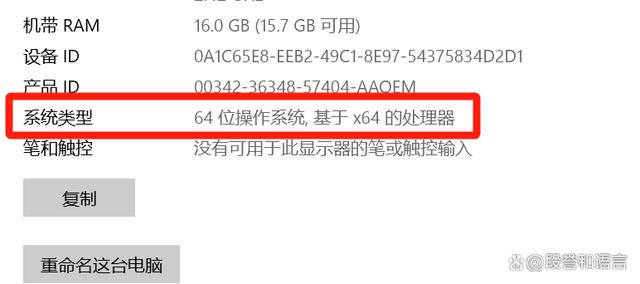
我们平时安装操作系统时都需要考虑是安装32位的操作系统还是64位的操作系统(当然也有8位、16位,甚至128位等不同位数)。这个32位和64位中的“位”,我们又称为比特,即bit,简写为b,一般用作单位时必须小写,和后文的B以示区别。
1个比特位就是1个二进制位,可以存放0或者1两个二进制数。8个比特位等于1个字节,字节即Byte,简写为B,必须大写,和前文的b区别开,2个字节就是1个字,字即WORD,2个字我们也称为双字,可以表示为Double Word,简写为DWORD。32位表示4个字节,64位表示8个字节。
1bit == 1b
8b == 1Byte
2Byte == 1WORD
2WORD == 1DWORD
32bit == 4Byte
64bit == 8Byte
CPU的字长
操作系统为什么会有32位或64位的区别呢?
这还要从CPU讲起。我们把CPU一次性处理数据的最大位数,称为CPU的字长。比如CPU字长为32bit,就是说CPU能够一次性处理4个字节的数据,CPU字长为64位,就是一次性能够处理8个字节的数据。64位CPU在理论上可以更快速地处理更多的数据。
CPU的字长一般可以换算为2的n次方的运算结果,也就是说CPU的字长只可能为2的0次方、2的1次方、2的2次方以此类推,即1、2、4、8、16、32、64、128等等。
操作系统的位数
而我们一般都是通过操作系统来控制和使用CPU,如果CPU是32位字长,那么操作系统就必须是32位的,才能正常工作。
如果CPU字长时64位的,那么操作系统就应该也是64位的,如果安装32位的操作系统,虽然也能使用,但是就无法充分使用64位CPU的性能优势。
一般情况下,CPU的字长和操作系统的位数要保持一致,才能达到最佳效果。
应用程序的位数
应用程序和操作系统一样,也有位数之分,在远古的DOS时代,应用程序一般是16位的,目前主要是32位和64位,在嵌入式领域还有8位的应用程序。
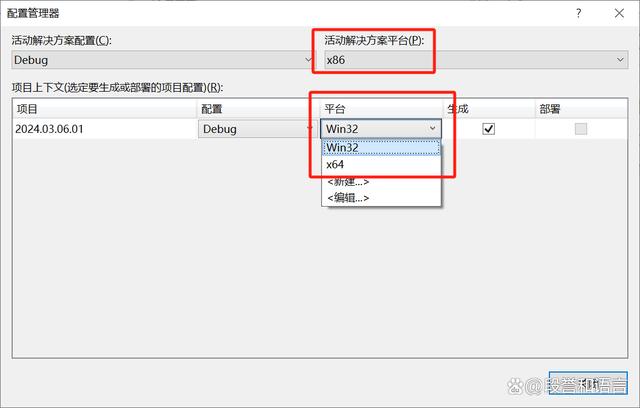
如果操作系统是32位系统,那么安装的编译器必须是32位版本的,源代码会被编译成32位应用程序,如果是64位操作系统,安装的编译器版本可以是32位或64位的,源代码也将由编译器的版本来确定是编译成32位还是64位。
微软的visual studio IDE,可以非常方便的切换x86和x64两种模式,x86模式编译的是32位应用程序,x64编译的是64位应用程序。
数据总线的宽度
CPU与其它硬件之间,都需要通过数据总线进行数据的传输。比如CPU与内存之间,CPU与输入输出接口之间,内存与输入输出接口之间等。
1根数据总线在同一时间只能传输1个比特的数据,数据总线的宽度指的是数据总线的根数,如果是数据总线是32位的,则意味着同一时间硬件之间可以同时传输32位数据。
一般情况下,数据总线的宽度和CPU的字长是匹配的,但并总是完全一致的。如果CPU字长是64位的,数据宽度32位,意味着CPU虽然可以一次性可以处理8个字节的数据,但每次通过数据总线只能读取4个字节,也就是必须读取2次数据,才能满足CPU一次的处理能力。反之,意味着虽然一次性可以传输8个字节数据给到CPU,但CPU需要2次才能处理完成。
内存寻址
内存中的每个字节都有一个固定地址,当变量被存放在内存中时,比如这个变量是int类型,假设在内存中占据4个字节,它在内存中的第一个字节的内存地址就是这个变量的内存地址,即使其他3个字节也有内存地址。
所谓“内存寻址”,就是在内存中寻找某个变量的内存地址的过程。
32位操作系统的数据总线宽度也是32位,又因为2的32次方等于4,294,967,296,假设32个比特位,从全部为0开始(32个0),一直排列组合到全部为1(32个1),一共大约有42亿组数字,每组数字代表内存中某个字节的地址,从0开始,一共可以表示4GB的内存地址。
刚才的例子是说如果数据总线是32位,则内存最多有4GB的地址,但是我们可以继续增加内容量,假如内存容量有6G,剩下的2G内存将无法被操作系统使用,因此32位操作系统的内存寻址能力(寻找内存地址)最大能力是4GB。64位操作系统支持的内存寻址能力最大可以达到2的64次方。
段誉,2024年3月8日,写于合肥。